[요약정리]딥 러닝을 이용한 자연어 처리 입문(Ch11. 스팸 메일 분류하기)
RNN을 이용해서 간단하게 스펨 메일 분류기를 구현해 보자
참고 사이트 : 딥 러닝을 이용한 자연어 처리 입문 에 대한 글을 요약하였다.
CH11. 텍스트 분류(Text Classification)
스팸 메일 분류하기(Spam Detection)
1. 스팸 메일 데이터에 대한 이해
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
data = pd.read_csv('data/spam.csv',encoding='latin1')
data[:5]
| v1 | v2 | Unnamed: 2 | Unnamed: 3 | Unnamed: 4 | |
|---|---|---|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only ... | NaN | NaN | NaN |
| 1 | ham | Ok lar... Joking wif u oni... | NaN | NaN | NaN |
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina... | NaN | NaN | NaN |
| 3 | ham | U dun say so early hor... U c already then say... | NaN | NaN | NaN |
| 4 | ham | Nah I don't think he goes to usf, he lives aro... | NaN | NaN | NaN |
# 필요한 v1, v2만 가져오고 v1은 레이블 0,1로 변환
del data['Unnamed: 2']
del data['Unnamed: 3']
del data['Unnamed: 4']
data['v1'] = data['v1'].replace(['ham','spam'],[0,1])
data[:5]
# 해당 data 정보 보기
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5572 entries, 0 to 5571
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 v1 5572 non-null int64
1 v2 5572 non-null object
dtypes: int64(1), object(1)
memory usage: 87.2+ KB
# null값 확인
data.isnull().values.any()
False
# 데이터 중복 확인
data['v2'].nunique(), data['v1'].nunique()
(5169, 2)
5572 샘플 중 403개는 중복됨
data['v1'].value_counts().plot(kind='bar');
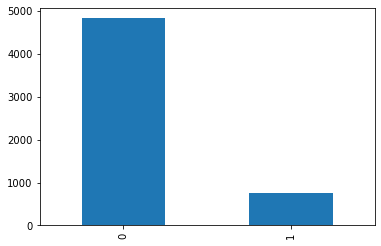
print(data.groupby('v1').size().reset_index(name='count'))
v1 count
0 0 4825
1 1 747
X_data = data['v2']
y_data = data['v1']
print('메일 본문의 개수: {}'.format(len(X_data)))
print('레이블의 개수: {}'.format(len(y_data)))
메일 본문의 개수: 5572
레이블의 개수: 5572
print('메일 본문의 개수: {}, 레이블의 개수: {}'.format(len(X_data), len(y_data)))
메일 본문의 개수: 5572, 레이블의 개수: 5572
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X_data) #5572개의 행을 가진 X의 각 행에 토큰화를 수행
sequences = tokenizer.texts_to_sequences(X_data) #단어를 숫자값, 인덱스로 변환하여 저장
print(sequences[:5])
[[50, 469, 4410, 841, 751, 657, 64, 8, 1324, 89, 121, 349, 1325, 147, 2987, 1326, 67, 58, 4411, 144], [46, 336, 1495, 470, 6, 1929], [47, 486, 8, 19, 4, 796, 899, 2, 178, 1930, 1199, 658, 1931, 2320, 267, 2321, 71, 1930, 2, 1932, 2, 337, 486, 554, 955, 73, 388, 179, 659, 389, 2988], [6, 245, 152, 23, 379, 2989, 6, 140, 154, 57, 152], [1018, 1, 98, 107, 69, 487, 2, 956, 69, 1933, 218, 111, 471]]
word_to_index = tokenizer.word_index
print(word_to_index)
{'i': 1, 'to': 2, 'you': 3, 'a': 4, 'the': 5, 'u': 6, 'and': 7, 'in': 8, 'is': 9, 'me': 10, 'my': 11, 'for': 12, 'your': 13, 'it': 14, 'of': 15, 'call': 16, 'have': 17, 'on':
...
vocab_size = len(word_to_index)+1
print('단어 집합의 크기: {}'.format((vocab_size)))
단어 집합의 크기: 8921
n_of_train = int(5572 * 0.8)
n_of_test = int(5572 - n_of_train)
print(n_of_train)
print(n_of_test)
4457
1115
X_data = sequences
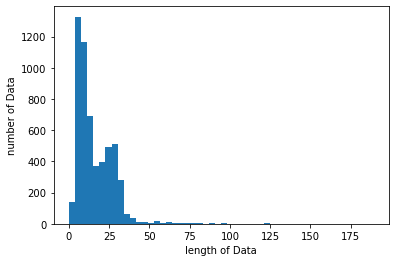
print('메일의 최대 길이 : %d' % max(len(l) for l in X_data))
print('메일의 평균 길이 : %f' % (sum(map(len, X_data))/len(X_data)))
plt.hist([len(s) for s in X_data], bins=50)
plt.xlabel('length of Data')
plt.ylabel('number of Data')
plt.show()
메일의 최대 길이 : 189
메일의 평균 길이 : 15.794867
max_len = 189
# 전체 데이터셋의 길이는 189로 맞춥니다.
data = pad_sequences(X_data, maxlen=max_len)
print("data shape: ", data.shape)
data shape: (5572, 189)
X_test = data[n_of_train:] #X_data 데이터 중에서 뒤의 1115개의 데이터만 저장
y_test = np.array(y_data[n_of_train:]) #y_data 데이터 중에서 뒤의 1115개의 데이터만 저장
X_train = data[:n_of_train] #X_data 데이터 중에서 앞의 4457개의 데이터만 저장
y_train = np.array(y_data[:n_of_train]) #y_data 데이터 중에서 앞의 4457개의 데이터만 저장
2. RNN으로 스팸 메일 분류하기
from tensorflow.keras.layers import SimpleRNN, Embedding, Dense
from tensorflow.keras.models import Sequential
model = Sequential()
model.add(Embedding(vocab_size, 32)) # 임베딩 벡터의 차원은 32
model.add(SimpleRNN(32)) # RNN 셀의 hidden_size는 32
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(X_train, y_train, epochs=4, batch_size=64, validation_split=0.2)
Train on 3565 samples, validate on 892 samples
Epoch 1/4
3565/3565 [==============================] - 4s 1ms/sample - loss: 0.3441 - acc: 0.8906 - val_loss: 0.2507 - val_acc: 0.9013
Epoch 2/4
3565/3565 [==============================] - 2s 607us/sample - loss: 0.0987 - acc: 0.9762 - val_loss: 0.0720 - val_acc: 0.9798
Epoch 3/4
3565/3565 [==============================] - 2s 626us/sample - loss: 0.0486 - acc: 0.9888 - val_loss: 0.0515 - val_acc: 0.9865
Epoch 4/4
3565/3565 [==============================] - 2s 618us/sample - loss: 0.0304 - acc: 0.9930 - val_loss: 0.0453 - val_acc: 0.9865
print("\n 테스트 정확도: %.4f" % (model.evaluate(X_test, y_test)[1]))
1115/1115 [==============================] - 1s 927us/sample - loss: 0.0531 - acc: 0.9839
테스트 정확도: 0.9839
epochs = range(1, len(history.history['acc']) + 1)
plt.plot(epochs, history.history['loss'])
plt.plot(epochs, history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()
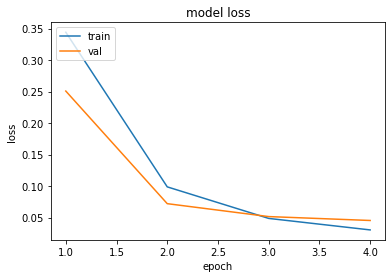
데이터의 양이 적어 과적합이 빠르게 시작 되므로 검증 데이터에 대한 오차가 시작하는 시점의 바로 직전인 3~4정도가 적당
