[파이썬] 파이썬 데이터 사이언스 핸드북 정리(나이브 베이즈)
파이썬 데이터 사이언스 핸드북 -제이크 밴더플래스- -위키북스- P437 ~ P444까지 (나이브 베이즈 분류 관련)
심화 학습 : 나이브 베이즈 분류
빠르다, 모수가 적다, 유용하다
P(feature Li)를 계산할 수 있는 모델이 필요하다.(생성모델이라고 한다.) - 데이터를 생성하는 가설적인 랜덤 프로세스를 기술
- 각 레이블에 대한 생성모델을 지정 하는 것이 베이즈 분류기를 훈련시키는 주요 부분
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
from sklearn.datasets import make_blobs
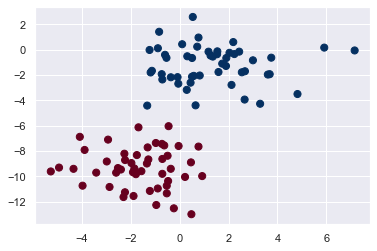
X, y = make_blobs(100, 2, centers=2, random_state=2, cluster_std=1.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='RdBu') # s는 c는 색상(y에 따라 색상 변화주기위함), 마커의 크기
<matplotlib.collections.PathCollection at 0x1b6bbfdaa08>
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X,y);
rng = np.random.RandomState(0)
Xnew = [-6, -14] + [14, 18]*rng.rand(2000, 2) # -6 + 14*랜덤값 계속
ynew = model.predict(Xnew) # 가우스나이브 모델
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='RdBu')
lim = plt.axis()
plt.scatter(Xnew[:, 0], Xnew[:, 1], c=ynew, s=20, cmap='RdBu', alpha=0.1)
plt.axis(lim)
(-5.902170524311957, 7.789182875858786, -13.793829460308247, 3.381339464828492)
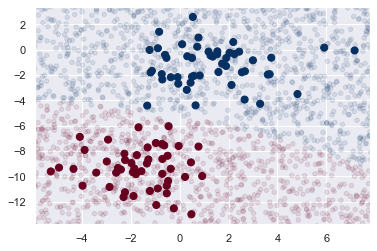
yprob = model.predict_proba(Xnew)
yprob[-8:].round(2) # 사후확률을 제공한다.
array([[0.89, 0.11],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[0.15, 0.85]])
다항분포 나이브 베이즈
개념은 나이브 베이즈와 같은데 다른점은 데이터 분포를 모델링하는 대신 최적합 다항식 분포로 모델링
예제 : 텍스트 분류
from sklearn.datasets import fetch_20newsgroups
data = fetch_20newsgroups()
data.target_names
['alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc']
categories = ['talk.religion.misc', 'soc.religion.christian', 'sci.space', 'comp.graphics']
train = fetch_20newsgroups(subset='train', categories=categories)
test = fetch_20newsgroups(subset='test', categories=categories)
print(train.data[5])
From: dmcgee@uluhe.soest.hawaii.edu (Don McGee)
Subject: Federal Hearing
Originator: dmcgee@uluhe
Organization: School of Ocean and Earth Science and Technology
Distribution: usa
Lines: 10
Fact or rumor....? Madalyn Murray O'Hare an atheist who eliminated the
use of the bible reading and prayer in public schools 15 years ago is now
going to appear before the FCC with a petition to stop the reading of the
Gospel on the airways of America. And she is also campaigning to remove
Christmas programs, songs, etc from the public schools. If it is true
then mail to Federal Communications Commission 1919 H Street Washington DC
20054 expressing your opposition to her request. Reference Petition number
2493.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
model.fit(train.data, train.target)
labels = model.predict(test.data)
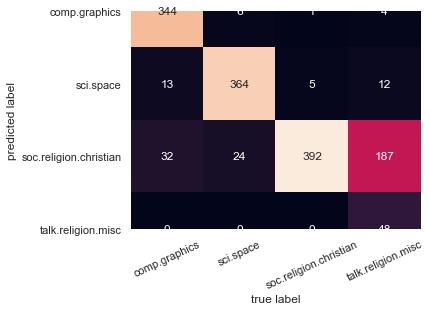
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(test.target, labels)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=train.target_names, yticklabels=train.target_names)
plt.xticks(rotation=25)
plt.xlabel('true label')
plt.ylabel('predicted label');
# 예측 범주를 반환하는 함수 만들기
def predict_category(s, train=train, model=model) :
pred = model.predict([s])
return train.target_names[pred[0]]
predict_category('sending a payload to the ISS')
'sci.space'
predict_category('discussing islam vs atheism')
'soc.religion.christian'
