[파이썬]캐글 타이타닉 데이터 탐색 #9, #10(Feature Engineering)
캐글 타이타닉 데이터 탐색 #9, #10(Feature Engineering)
#9, #10 동영상에서는 Fill Null in Age와 Fill NUll in Embarked and Categorize Age를 한다.
참고 : You Han Lee 유튜브
df_train['Age'].isnull().sum()
177
df_train['Initial']= df_train['Name'].str.extract('([A-Za-z]+)\.') # 점 앞에꺼를 가져오겠다.
df_test['Initial']= df_test['Name'].str.extract('([A-Za-z]+)\.') # 점 앞에꺼를 가져오겠다.
df_train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | FamilySize | initial | Initial | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 1.981001 | NaN | S | 2 | Mr | Mr |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 4.266662 | C85 | C | 2 | Mrs | Mrs |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 2.070022 | NaN | S | 1 | Miss | Miss |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 3.972177 | C123 | S | 2 | Mrs | Mrs |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 2.085672 | NaN | S | 1 | Mr | Mr |
pd.crosstab(df_train['Initial'], df_train['Sex']).T.style.background_gradient(cmap='summer_r')
| Initial | Capt | Col | Countess | Don | Dr | Jonkheer | Lady | Major | Master | Miss | Mlle | Mme | Mr | Mrs | Ms | Rev | Sir |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sex | |||||||||||||||||
| female | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 182 | 2 | 1 | 0 | 125 | 1 | 0 | 0 |
| male | 1 | 2 | 0 | 1 | 6 | 1 | 0 | 2 | 40 | 0 | 0 | 0 | 517 | 0 | 0 | 6 | 1 |
df_train['Initial'].replace(['Mile', 'Mme', 'Ms', 'Dr', 'Major','Lady', 'Countess', 'Jonkheer', 'Col', 'Rev', 'Capt', 'Sir', 'Don', 'Dona'],
['Miss', 'Miss', 'Miss', 'Mr', 'Mr', 'Mrs', 'Mrs', 'Other', 'Other', 'Other', 'Mr', 'Mr', 'Mr', 'Mr'], inplace=True)
df_test['Initial'].replace(['Mile', 'Mme', 'Ms', 'Dr', 'Major','Lady', 'Countess', 'Jonkheer', 'Col', 'Rev', 'Capt', 'Sir', 'Don', 'Dona'],
['Miss', 'Miss', 'Miss', 'Mr', 'Mr', 'Mrs', 'Mrs', 'Other', 'Other', 'Other', 'Mr', 'Mr', 'Mr', 'Mr'], inplace=True)
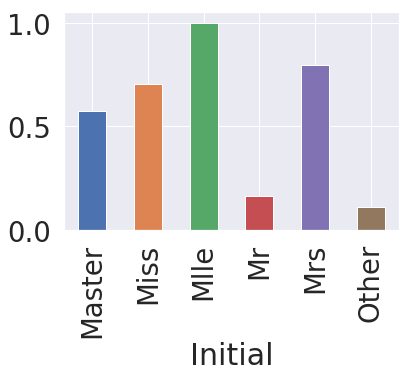
df_train.groupby('Initial').mean()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | FamilySize | |
|---|---|---|---|---|---|---|---|---|
| Initial | ||||||||
| Master | 414.975000 | 0.575000 | 2.625000 | 4.574167 | 2.300000 | 1.375000 | 3.340710 | 4.675000 |
| Miss | 408.864130 | 0.701087 | 2.298913 | 21.831081 | 0.706522 | 0.543478 | 3.113425 | 2.250000 |
| Mlle | 676.500000 | 1.000000 | 1.000000 | 24.000000 | 0.000000 | 0.000000 | 4.070251 | 1.000000 |
| Mr | 455.880907 | 0.162571 | 2.381853 | 32.739609 | 0.293006 | 0.151229 | 2.651507 | 1.444234 |
| Mrs | 456.393701 | 0.795276 | 1.984252 | 35.981818 | 0.692913 | 0.818898 | 3.443751 | 2.511811 |
| Other | 564.444444 | 0.111111 | 1.666667 | 45.888889 | 0.111111 | 0.111111 | 2.641605 | 1.222222 |
df_train.groupby('Initial')['Survived'].mean().plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x7fde203fc5f8>
df_all = pd.concat([df_train, df_test])
df_all.head()
| Age | Cabin | Embarked | FamilySize | Fare | Initial | Name | Parch | PassengerId | Pclass | Sex | SibSp | Survived | Ticket | initial | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 22.0 | NaN | S | 2.0 | 1.981001 | Mr | Braund, Mr. Owen Harris | 0 | 1 | 3 | male | 1 | 0.0 | A/5 21171 | Mr |
| 1 | 38.0 | C85 | C | 2.0 | 4.266662 | Mrs | Cumings, Mrs. John Bradley (Florence Briggs Th... | 0 | 2 | 1 | female | 1 | 1.0 | PC 17599 | Mrs |
| 2 | 26.0 | NaN | S | 1.0 | 2.070022 | Miss | Heikkinen, Miss. Laina | 0 | 3 | 3 | female | 0 | 1.0 | STON/O2. 3101282 | Miss |
| 3 | 35.0 | C123 | S | 2.0 | 3.972177 | Mrs | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 0 | 4 | 1 | female | 1 | 1.0 | 113803 | Mrs |
| 4 | 35.0 | NaN | S | 1.0 | 2.085672 | Mr | Allen, Mr. William Henry | 0 | 5 | 3 | male | 0 | 0.0 | 373450 | Mr |
df_all.groupby('Initial').mean()
| Age | FamilySize | Fare | Parch | PassengerId | Pclass | SibSp | Survived | |
|---|---|---|---|---|---|---|---|---|
| Initial | ||||||||
| Master | 5.482642 | 4.675000 | 15.442677 | 1.377049 | 658.852459 | 2.655738 | 2.049180 | 0.575000 |
| Miss | 21.814104 | 2.250000 | 14.096861 | 0.498099 | 616.539924 | 2.342205 | 0.657795 | 0.701087 |
| Mlle | 24.000000 | 1.000000 | 4.070251 | 0.000000 | 676.500000 | 1.000000 | 0.000000 | 1.000000 |
| Mr | 32.556397 | 1.444234 | 10.003941 | 0.159533 | 658.831388 | 2.359274 | 0.286641 | 0.162571 |
| Mrs | 37.034884 | 2.511811 | 23.896996 | 0.824121 | 685.673367 | 1.929648 | 0.658291 | 0.795276 |
| Other | 44.923077 | 1.222222 | 24.523034 | 0.153846 | 714.923077 | 1.615385 | 0.230769 | 0.111111 |
# 두번째(1)로우의 값을 가져와 달라 (location을 쓰는것)
df_train.loc[1, :]
PassengerId 2
Survived 1
Pclass 1
Name Cumings, Mrs. John Bradley (Florence Briggs Th...
Sex female
Age 38
SibSp 1
Parch 0
Ticket PC 17599
Fare 4.26666
Cabin C85
Embarked C
FamilySize 2
initial Mrs
Initial Mrs
Name: 1, dtype: object
# 로케이션 이용해서 Survived가 1인것들만 가져옴
df_train.loc[df_train['Survived'] ==1 ].head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | FamilySize | initial | Initial | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 4.266662 | C85 | C | 2 | Mrs | Mrs |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 2.070022 | NaN | S | 1 | Miss | Miss |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 3.972177 | C123 | S | 2 | Mrs | Mrs |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 2.409941 | NaN | S | 3 | Mrs | Mrs |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 3.403555 | NaN | C | 2 | Mrs | Mrs |
df_train.loc[(df_train['Age'].isnull()) & (df_train['Initial'] == 'Mr')].head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | FamilySize | initial | Initial | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 2.135148 | NaN | Q | 1 | Mr | Mr |
| 17 | 18 | 1 | 2 | Williams, Mr. Charles Eugene | male | NaN | 0 | 0 | 244373 | 2.564949 | NaN | S | 1 | Mr | Mr |
| 26 | 27 | 0 | 3 | Emir, Mr. Farred Chehab | male | NaN | 0 | 0 | 2631 | 1.977547 | NaN | C | 1 | Mr | Mr |
| 29 | 30 | 0 | 3 | Todoroff, Mr. Lalio | male | NaN | 0 | 0 | 349216 | 2.066331 | NaN | S | 1 | Mr | Mr |
| 36 | 37 | 1 | 3 | Mamee, Mr. Hanna | male | NaN | 0 | 0 | 2677 | 1.978128 | NaN | C | 1 | Mr | Mr |
# 조건을 만족하는거를 치환
df_train.loc[(df_train['Age'].isnull()) & (df_train['Initial'] == 'Mr'), 'Age'] = 33
df_train.loc[(df_train['Age'].isnull()) & (df_train['Initial'] == 'Mrs'), 'Age'] = 37
df_train.loc[(df_train['Age'].isnull()) & (df_train['Initial'] == 'Master'), 'Age'] = 5
df_train.loc[(df_train['Age'].isnull()) & (df_train['Initial'] == 'Miss'), 'Age'] = 22
df_train.loc[(df_train['Age'].isnull()) & (df_train['Initial'] == 'Other'), 'Age'] = 45
df_test.loc[(df_test['Age'].isnull()) & (df_test['Initial'] == 'Mr'), 'Age'] = 33
df_test.loc[(df_test['Age'].isnull()) & (df_test['Initial'] == 'Mrs'), 'Age'] = 37
df_test.loc[(df_test['Age'].isnull()) & (df_test['Initial'] == 'Master'), 'Age'] = 5
df_test.loc[(df_test['Age'].isnull()) & (df_test['Initial'] == 'Miss'), 'Age'] = 22
df_test.loc[(df_test['Age'].isnull()) & (df_test['Initial'] == 'Other'), 'Age'] = 45
df_train['Age'].isnull().sum()
0
df_test['Age'].isnull().sum()
0
df_train['Embarked'].isnull().sum()
2
df_train.shape
(891, 15)
df_train['Embarked'].fillna('S', inplace=True)
df_train['Embarked'].isnull().sum()
0
df_train['Age_cat'] = 0
df_train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | FamilySize | initial | Initial | Age_cat | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 1.981001 | NaN | S | 2 | Mr | Mr | 0 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 4.266662 | C85 | C | 2 | Mrs | Mrs | 0 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 2.070022 | NaN | S | 1 | Miss | Miss | 0 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 3.972177 | C123 | S | 2 | Mrs | Mrs | 0 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 2.085672 | NaN | S | 1 | Mr | Mr | 0 |
# 하드 코딩을 하는데 너무 어렵다.
df_train.loc[df_train['Age'] < 10, 'Age_cat'] = 0
df_train.loc[(10 <= df_train['Age']) & (df_train['Age'] < 20), 'Age_cat'] = 1
df_train.loc[(20 <= df_train['Age']) & (df_train['Age'] < 30), 'Age_cat'] = 2
df_train.loc[(30 <= df_train['Age']) & (df_train['Age'] < 40), 'Age_cat'] = 3
df_train.loc[(40 <= df_train['Age']) & (df_train['Age'] < 50), 'Age_cat'] = 4
df_train.loc[(50 <= df_train['Age']) & (df_train['Age'] < 60), 'Age_cat'] = 5
df_train.loc[(60 <= df_train['Age']) & (df_train['Age'] < 70), 'Age_cat'] = 6
df_train.loc[(70 <= df_train['Age']), 'Age_cat'] = 7
df_test.loc[df_test['Age'] < 10, 'Age_cat'] = 0
df_test.loc[(10 <= df_test['Age']) & (df_test['Age'] < 20), 'Age_cat'] = 1
df_test.loc[(20 <= df_test['Age']) & (df_test['Age'] < 30), 'Age_cat'] = 2
df_test.loc[(30 <= df_test['Age']) & (df_test['Age'] < 40), 'Age_cat'] = 3
df_test.loc[(40 <= df_test['Age']) & (df_test['Age'] < 50), 'Age_cat'] = 4
df_test.loc[(50 <= df_test['Age']) & (df_test['Age'] < 60), 'Age_cat'] = 5
df_test.loc[(60 <= df_test['Age']) & (df_test['Age'] < 70), 'Age_cat'] = 6
df_test.loc[(70 <= df_test['Age']), 'Age_cat'] = 7
df_train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | FamilySize | initial | Initial | Age_cat | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 1.981001 | NaN | S | 2 | Mr | Mr | 2 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 4.266662 | C85 | C | 2 | Mrs | Mrs | 3 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 2.070022 | NaN | S | 1 | Miss | Miss | 2 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 3.972177 | C123 | S | 2 | Mrs | Mrs | 3 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 2.085672 | NaN | S | 1 | Mr | Mr | 3 |
def category_age(x):
if x < 10:
return 0
elif x < 20:
return 1
elif x < 30:
return 2
elif x < 40:
return 3
elif x < 50:
return 4
elif x < 60:
return 5
elif x < 70:
return 6
else:
return 7
df_train['Age_cat_2'] = df_train['Age'].apply(category_age)
# 하드 코딩과 같은 결과를 내는지 봄
(df_train['Age_cat'] == df_train['Age_cat_2']).all()
True
df_train.drop(['Age', 'Age_cat_2'], axis=1, inplace=True)
df_test.drop(['Age'], axis=1, inplace=True)
