[파이썬]캐글 타이타닉 데이터 탐색 #7, #8(FamilySize, Fare, Cabin, Ticket)
캐글 타이타닉 데이터 탐색 #7, #8(FamilySize, Fare, Cabin, Ticket)
#7, #8 동영상에서 FamilySize, Fare, Cabin, Ticket을 마지막으로 EDA 마친다.
참고 : You Han Lee 유튜브
Family - SibSp + Parch
# Familysize를 SibSp와 Parch 그리고 자신까지 더한다.
df_train['FamilySize'] = df_train['SibSp'] + df_train['Parch'] + 1
print('Maximum size of Family: ', df_train['FamilySize'].max())
print('Minimum size of Family: ', df_train['FamilySize'].min())
Maximum size of Family: 11
Minimum size of Family: 1
f, ax = plt.subplots(1, 3, figsize=(40,10))
sns.countplot('FamilySize', data=df_train, ax=ax[0])
ax[0].set_title('(1) No. Of Passenger Boarded', y=1.02)
sns.countplot('FamilySize', hue='Survived', data=df_train, ax=ax[1]) # hue로 색깔로 Survived 나눔
ax[1].set_title('(2) Survived countplot depending on FamilySize', y=1.02)
df_train[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=True).mean().sort_values(by='Survived', ascending=False).plot.bar(ax=ax[2])
ax[2].set_title('(3) Survived rate depending on FamilySize', y=1.02)
plt.subplots_adjust(wspace=0.2, hspace=0.5)
plt.show()
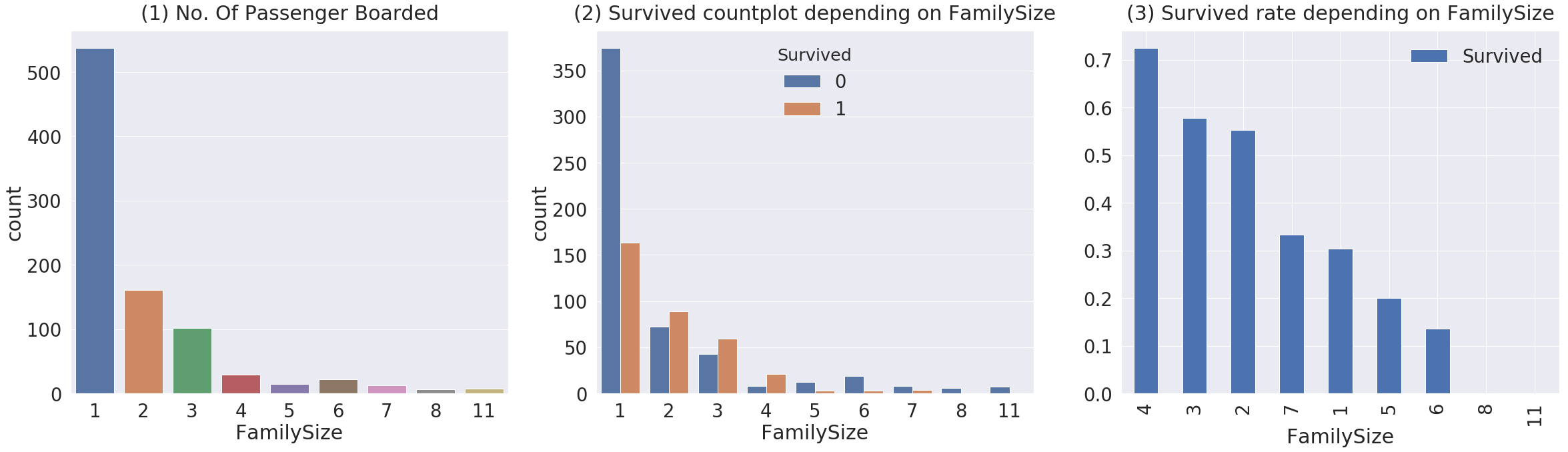
해설 : 혼자 탄 사람이 많고, 8, 11 가족은 생존한 확률이 없다. 2~4인가족이 많이 살았다.
Fare
# dist플랏을 그리고 왜도(얼마나 쏠렸는가, 비대칭)를 그려주기
fig, ax = plt.subplots(1, 1, figsize=(8,8))
g = sns.distplot(df_train['Fare'], color='b', label='Skewness: {:.2f}'.format(df_train['Fare'].skew()), ax=ax)
g = g.legend(loc='best') # Skewness 위치를 베스트로 놔둔다., g 그림 객체를 말하는거임
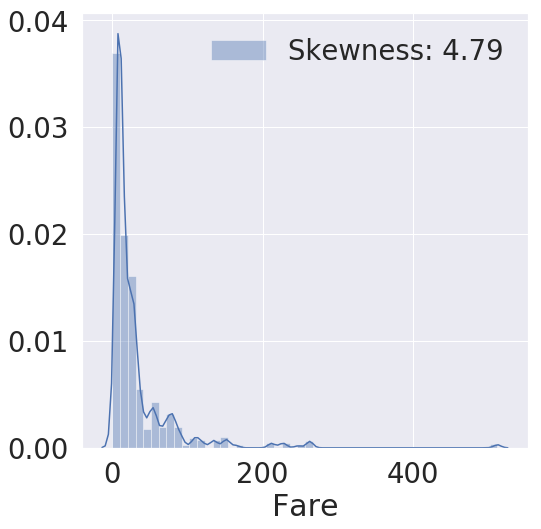
# 어플라이는 함수를 넣어주고, map은 람다나 딕셔너리를 넣어준다.
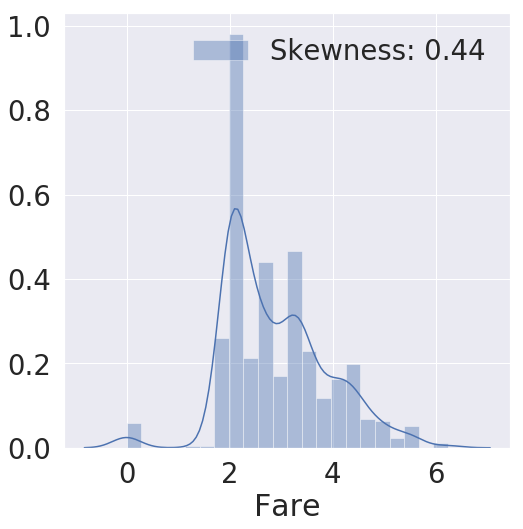
# 로그 정규화함
df_train['Fare'] = df_train['Fare'].map(lambda i: np.log(i) if i>0 else 0)
# 만약에 0 이상이면 로그를 취한다.
fig, ax = plt.subplots(1, 1, figsize=(8,8))
g = sns.distplot(df_train['Fare'], color='b', label='Skewness: {:.2f}'.format(df_train['Fare'].skew()), ax=ax)
g = g.legend(loc='best') # Skewness 위치를 베스트로 놔둔다.
# 티켓은 너무 많다. 어떤 묶어야되는 그런 방안을 생각해봐야겠다.
df_train['Ticket'].value_counts().head(10)
CA. 2343 7
347082 7
1601 7
3101295 6
CA 2144 6
347088 6
S.O.C. 14879 5
382652 5
PC 17757 4
347077 4
Name: Ticket, dtype: int64
